
NVIDIA B200
An inference monster. A training behemoth.
And, out of stock almost everywhere (packet.ai is one exception: new SKUs coming soon).
Why is the best mainstream GPU so hard to find – and what we can do about it?

Everyone wants B200 GPUs
B300s aren’t in widespread circulation yet, so the B200 reigns supreme.
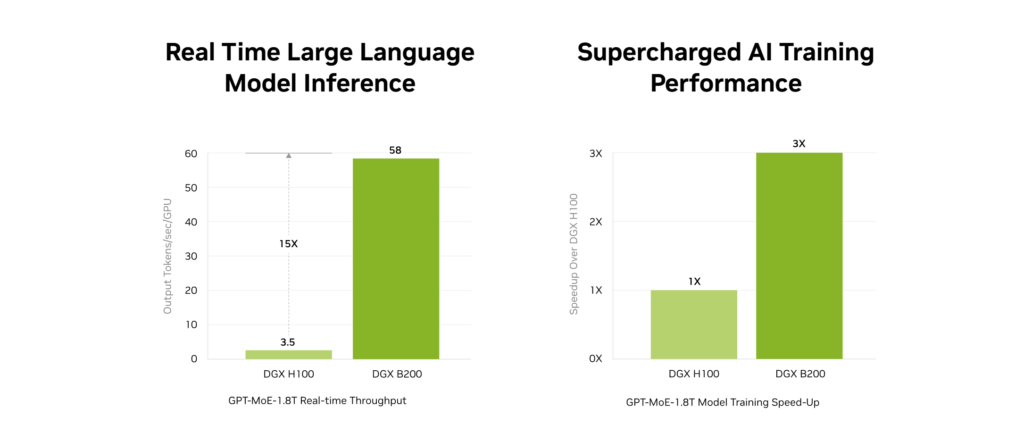
In tests, it annihilates older GPUs like H100. NVIDIA claims 15x performance in LLM inference and 3x in training.
Independent benchmarks seem to validate this. However, it’s kind of irrelevant if you can’t actually rent one for your project.
Why are B200s so scarce?

While hyperscalers have sucked up a lot of the available B200 supply, the lack of B200 isn’t really about the GPU supply chain.
B200s are scarce because of the basic problem with GPU orchestration:
There is no GPU orchestration.
In most neoclouds, GPU is provisioned as a static resource. You can rent a fixed instance, a single GPU, a server or a cluster, but you cannot rent the GPU capacity you need.
You’re renting physical hardware, not compute.
Everything else in the stack is an elastic, software-defined resource: CPU, RAM, storage, network. Not GPU.
Those $40k B200s are just dumb lumps of silicon attached to a single VM or container.
B200s going to waste
In today’s neocloud model, each card is dedicated to a single tenant or workload. If you have fifty B200s, you can serve fifty users, regardless of how much compute those users actually need*.
Now, consider that on average, GPU utilization is about 40% across AI training, tuning and inference.
AI inference, where B200 really shines, is a highly variable workload and utilization hovers around 15% on average.
That’s a lot of GPU going to waste, and so:
- AI developers and AI enterprises are paying for GPU they aren’t using
- GPUaaS providers are buying super-expensive hardware that isn’t being fully utilized or monetized
- All those B200s are tied up in GPU clouds doing… nothing much, a lot of the time
(* Yes, you can use MIG, but that just creates more static instances)

Fixing GPU orchestration at the server level
This is the problem we solve at hosted·ai.
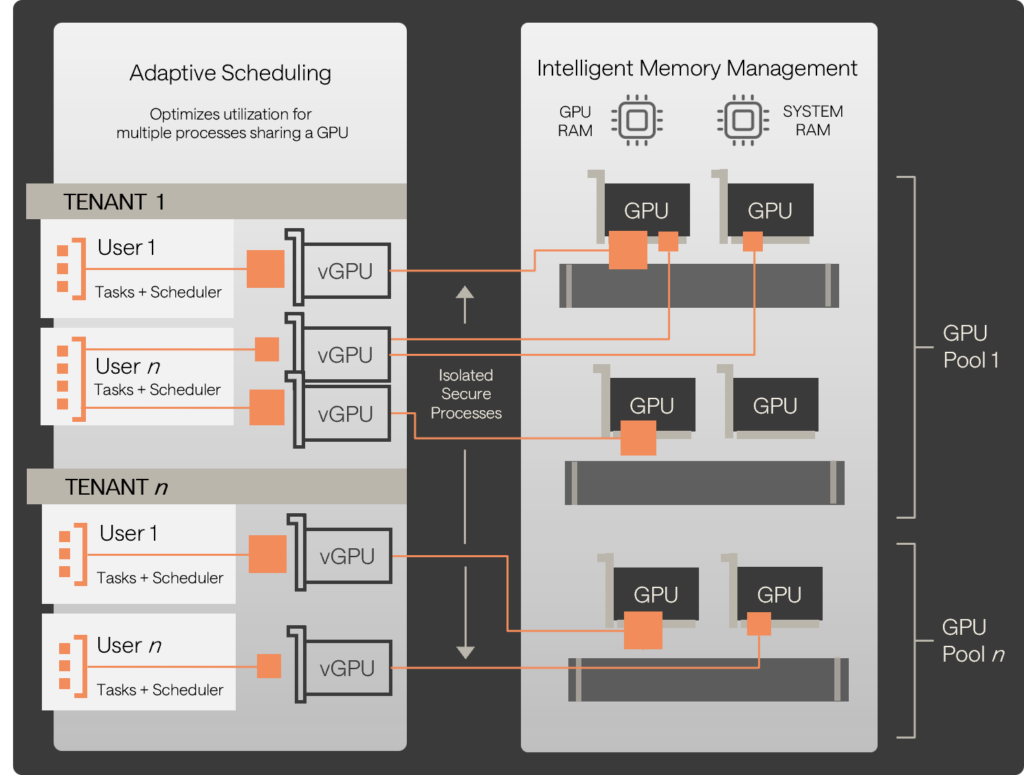
We’ve built a GPU control plane that creates an abstraction layer between physical GPUs and the end user workloads.
It takes B200s (or any recent GPU) and presents them as a pool of resource that can be provisioned to multiple tenants simultaneously.
- It makes GPU work like cloud – just like CPU, storage and networking works in any infrastructure-as-a-service scenario
- Each individual GPU can now power multiple tenant workloads
- With the addition of GPU overcommit, utilization can be optimized towards 100%, which means no more idle capacity
Fixing GPU orchestration at the ecosystem level
That optimization is at the GPU or GPU server level, but it also goes further.
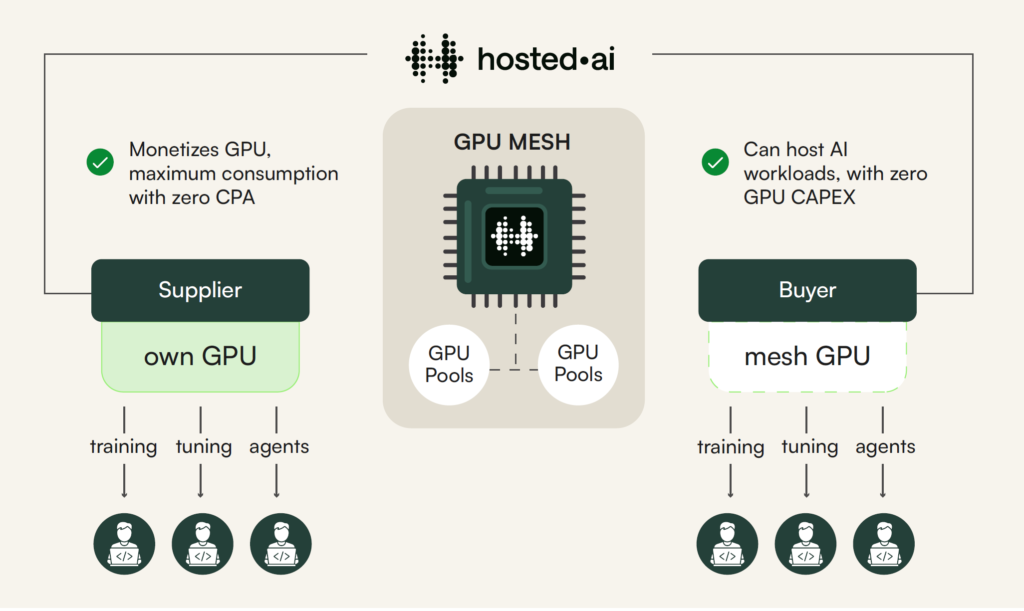
We’ve built a capacity sharing system for GPU cloud providers (aka, neoclouds).
It’s called GPU Mesh.
Now service providers can publish their B200 (or any recent GPU) pools to the Mesh, and monetize their spare capacity.
And, service providers that don’t have B200s – or just don’t have GPU at scale – can subscribe to those pools, and resell them to their customers.
A step change in efficiency – transforming GPU economics
Put those two things together – the step-change in efficiency for GPU orchestration, and the ability to share capacity – and we solve the problem for B200s, B300s, and whatever comes next.
That’s how we make GPU globally accessible. That’s how we prevent waste, not just of GPU cycles, but of silicon and energy too.
And, that’s how we make GPUaaS more affordable, because the same silicon can serve more customers simultaneously than ever before.
Efficient GPU orchestration drives down cost for GPU buyers, and drives down the CAPEX and OPEX for GPU cloud providers – which in turn makes them more profitable.
(Incidentally, that’s why Packet.ai offers B200 as a service at much lower cost than any other provider, at the time of writing. If you need B200s, check it out).
For more information, get in touch for a chat or a demo – or follow the links below.
No idle GPUs. No brakes on innovation. No inflated bills.
Just ultra-efficient AI infrastructure.
A complete GPU cloud stack for neocloud service providers
Build ultra-efficient infrastructure to host AI workloads, with up to 100% GPU utilization and unbeatable ROI.
A neocloud offering B200 GPUaaS and more at ultra-low cost
Get GPU for AI development, training and inference, using efficient infrastructure powered by hosted·ai.
Wholesale GPU clusters at scale for enterprise AI
A GPU match-making service, offering AI infrastructure at market-leading rates, powered by hosted·ai.
With hosted·ai, we’re streamlining the provisioning experience for AI teams that need reliable, easy, and cost-effective infrastructure.
More Resources





Get a demo
We’ll walk/talk you through the platform, answer your questions and advise on the best next steps.