Version 2.4 of the hosted.ai GPUaaS platform is available now, bringing new ways to sell GPUaaS, and enhanced usability and stability for neoclouds and their customers. Let’s get into it!
#BuildingInPublic – the platform story so far
hosted.ai has rolled out a major platform update that makes it easier for teams to deploy, manage, and scale AI infrastructure across GPU services, virtual machines, and bare metal.
This update brings together several improvements that matter directly to operators, platform teams, and AI builders:
- better performance and scalability in core platform orchestration
- a more consistent provisioning and management experience across GPU services and VMs
- new bare metal GPU instance support
- browser-based SSH access across compute types
- stronger automation for GPU service deployments
- real-time Kubernetes service health visibility
The result is a platform that is easier to operate, more flexible for customers, and better suited for modern AI workloads ranging from inference and application hosting to distributed training and Kubernetes-based deployments.
New to hosted·ai? Learn more about our GPU cloud platform or get in touch for a demo.
What’s new in hosted·ai v2.4:
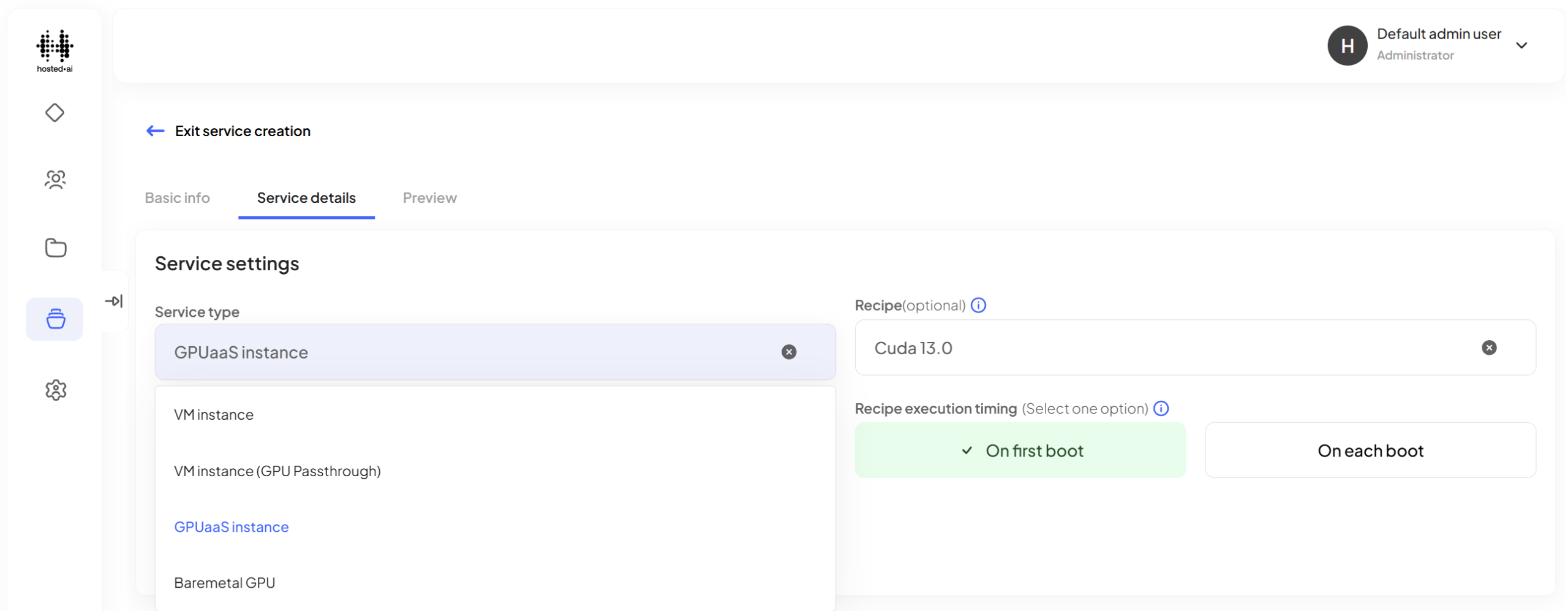
1. Sell bare metal GPU instances
v2.4 solidifies the bare metal GPU server management and instance provisioning capabilities that we introduced earlier this year.
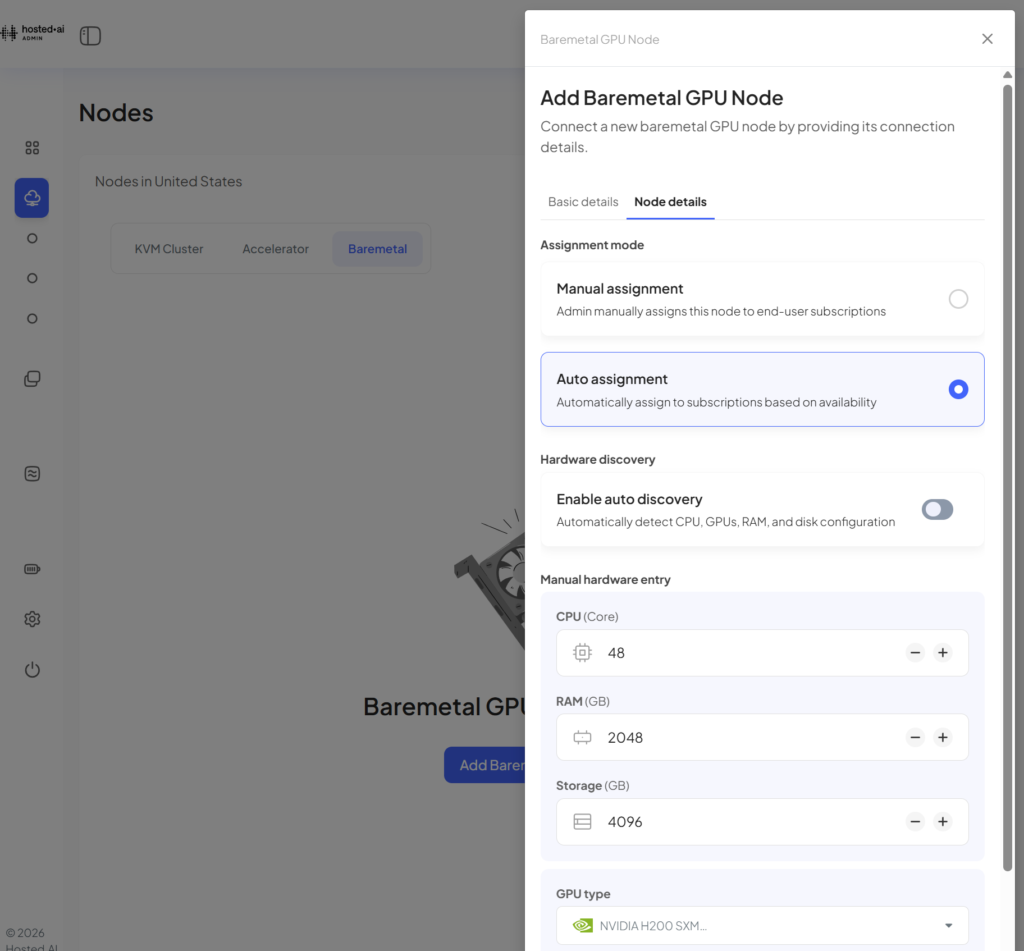
With hosted·ai, you can onboard bare metal GPU nodes and manage the full node lifecycle (offline → online → in service → not in service).
You can provision servers to users via auto-assignment, or by manual allocation from the admin panel.
Bare metal node billing is handled with the same hosted·ai billing engine you use for other flavors of GPU cloud (elastic GPUaaS, and GPU VMs).
Bare metal nodes include SSH console access, and provisioning is via Ansible. DCIM, coming soon.
What this means:
Through a single portal, you can now sell all flavors of GPU cloud – dedicated GPUaaS, shared GPUaaS, VMs with GPU passthrough, and bare metal GPU servers – with a consistent management UI and unified billing control.
2. Sell GPUaaS with user-selected and VIP GPU scheduling
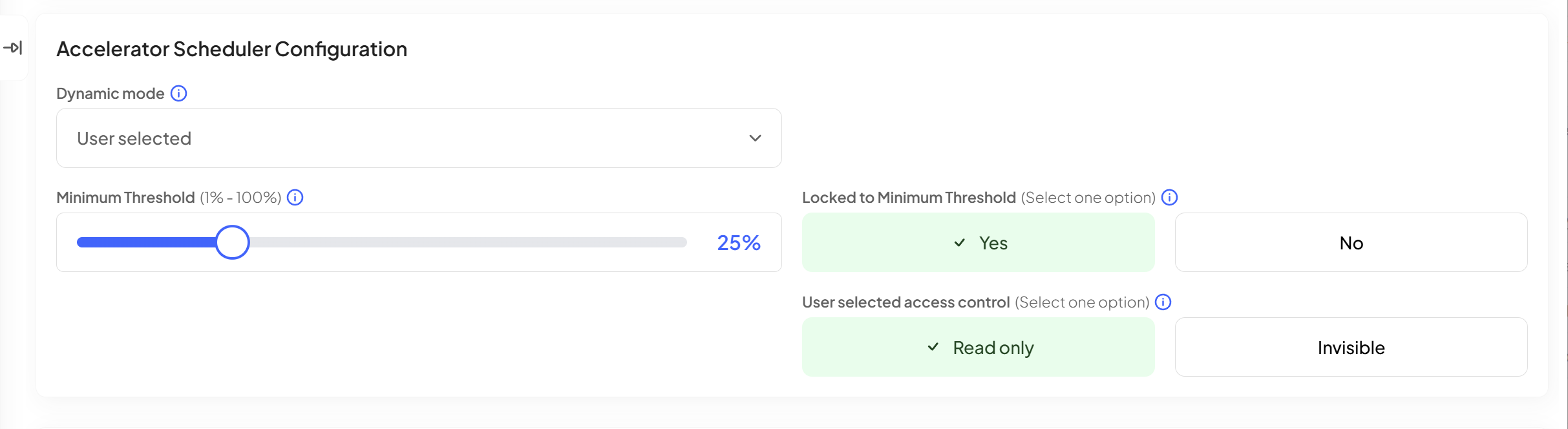
The hosted.ai platform has the most flexible GPU scheduling engine on the market. In v2.4, this has expanded with two new scheduling options that can be configured for your GPUaaS products:
Dynamic / user-selected GPU scheduling: this enables you to create GPUaaS products that give the user the ability to choose a minimum GPU resource percentage they will receive from a shared GPU pool. The hosted·ai scheduler guarantees that percentage of resources for their workloads, and the user is billed accordingly.
VIP priority scheduling: this enables you to create GPUaaS products with prioritized workload scheduling: VIP user workloads are prioritized when multiple tenants access a pool simultaneously, and the user is billed accordingly.
Why it matters:
These scheduling options help providers offer more predictability for multi-tenant workloads; offer premium/guaranteed offerings; and enable latency-sensitive inference workloads to co-exist with training workloads on multi-tenant GPU pools without impacting the end user experience.
3. RootFS persistence for GPUaaS pods
The root file system of GPUaaS pods can now be made persistent across reboots. This has been implemented using a host-path storage plugin. There is no separate remote volume, no periodic data sync, and zero performance overhead.
RootFS persistence is enabled by default on new instances:
- Ansible service execution runs the first time the system boots, but not on instance reboot
- A new ‘factory reset’ with data wipe feature has been implemented to fully erase persistent storage when required
- Storage quotas are enforced with sysbox (ENOSPC at 96% usage) to prevent pod out-of-storage crashes
- df/reboot wrappers are used for full VM-like behaviour inside pods, showing the actual usage for storage inside an instance
Why this is important:
It’s a big quality of life improvement for neoclouds and their developer customers: planned (or unplanned) pod reboots won’t lose installed packages, drivers, or configurations on restart. Hosted.ai GPUaaS pods now behave much like VM environments.
4. High Availability for KVM clusters
hosted·ai v2.4 introduces automatic primary/secondary failover for KVM cluster panel nodes, using etcd for distributed leader election. A periodic HA agent aligns controller services and SQL database replication to the elected leader without manual intervention. VMs can be individually set to auto-restart or not.
High Availability is enabled via a toggle in the hosted·ai cluster management panel. It enforces a 3-node minimum, and supports full disable/revert.
What this means:
High Availability improves SLA reliability for hosted VM infrastructure. It eliminates single points of failure in KVM cluster management, reduces unplanned downtime for VM workloads, and provides automated recovery without operator intervention on primary node failure.
5. Prometheus metrics framework for KVM
In hosted·ai v2.4, we have replaced the legacy RRD file-based stats system with a Prometheus + libvirt exporter architecture.
It provides per-VM metrics (vCPU, memory, disk I/O, network I/O) and cluster-wide node exporter metrics, with real-time dashboards, AlertManager webhook integration, and batch 10-minute collection. Prometheus configuration is auto-regenerated with a 10-second target sync, as nodes are added or removed.
How does this help?
This delivers a scalable, standards-based observability foundation for KVM infrastructure — eliminating filesystem scan overhead, enabling reliable alerting (node down, disk thresholds), and providing historical metric storage across all cluster nodes to support operational visibility at scale.
Next steps
This release also includes many smaller improvements and fixes based on customer feedback.
- To upgrade from previous versions to hosted·ai v2.4, please contact your account manager or our customer success team.
- If you’re new to hosted·ai, get in touch for a demo and we’ll walk/talk you through the platform. Thanks!