Five fundamentals to discuss with your GPU cloud platform provider
Traditional service providers need to evolve their offering from IaaS to GPUaaS. Neoclouds need to build the platform right, first time, to ensure a successful future. The GPU orchestration platform / control plane you choose is critical.
This guide helps you assess GPU cloud platform features against the success criteria of multi-tenant service providers (neoclouds, CSPs, hosts, telcos).
How to use this guide
Each section of the guide provides questions you can ask platform vendors about five fundamental feature categories that determine those success criteria:
Success criteria:
Control of service design, deployment model, branding, access, location
Flexible pricing – ability to price GPUaaS tiers for specific customer segments
Inference ready – enabling GPU to flex and scale like cloud for variable workloads
Ecosystem integration – ability to slot into existing provider workloads and tools
Profitability – optimal utilization, minimal operational overheads, maximum margins
Simple UX for admins and customers – easy management and consumption
hosted·ai was created for service provider GPUaaS. It is multi-tenant by design. Instead of just selling GPU on a card-by-card basis (one card per user) or a bare metal basis (one GPU server per user), you can assign physical GPUs to virtual GPU pools, and sell the resources of the pool to multiple tenants at once.
In the 2.0.1 release of hosted·ai we updated the hosted·ai task scheduler, which is the part of the platform that handles the crucial task of assigning GPU resources to user workloads. Let’s take a look at the task scheduler and how it works – but first, some basics…
The basics: how hosted·ai handles multi-tenant GPU virtualization
The GPU pooling concept is the foundation of our GPU cloud multi-tenancy. Through the hosted·ai admin panel, you create your regions, add your servers, and automatically detect the GPUs attached to those servers. Then you assign those GPUs to virtual GPU pools.
You can create private pools for the exclusive use of a single tenant – the GPUaaS equivalent of virtual private cloud. You can create GPU pools that are shared by multiple tenants – the GPUaaS equivalent of public cloud.
(with hosted·ai you can also sell GPU cards using traditional passthrough virtualization, if you deploy the platform as a full HCI stack running on KVM, but in this article we will just focus on the true multi-tenant GPUaaS scenarios.)
Each tenant can have its own team with multiple users, and each of those users can have their own quotas and access rights. Each user sees their own GPU device, can run the full CUDA tool stack, can run NVIDIA SMI and access the full capacity of each card. It’s fully software-defined GPU – you can read more about that in this software-defined GPU whitepaper.
Multi-tenant GPU task scheduling options
Ok, so how are all of these tenants and user tasks given access to the GPU resources they need, the GPU cycles, the VRAM and TFLOPs?
That’s the job of the task scheduler. It is an extremely efficient system that provides workloads with access to GPU resources.
The type of access is controlled by a range of settings the provider can configure for each GPU pool.
Using a few intuitive sliders, you can configure shared resources for optimal performance, security, or a blend of both.
By configuring different pool settings you can create GPUaaS for a wide range of customer use cases.
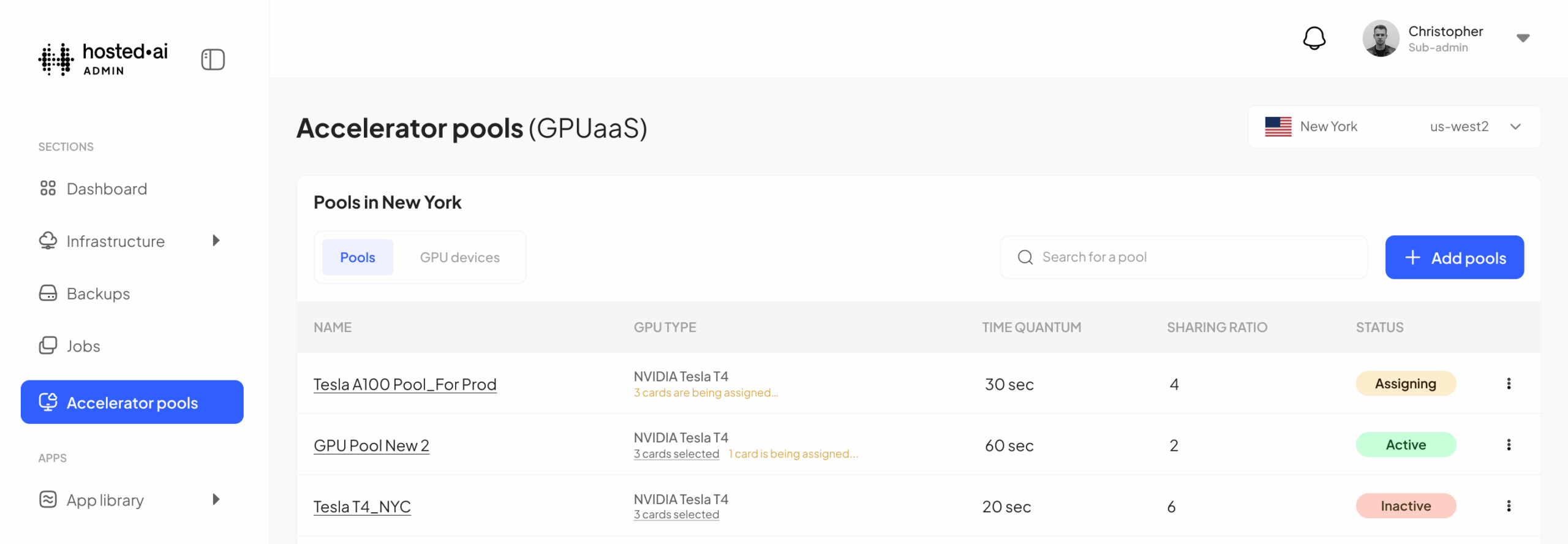
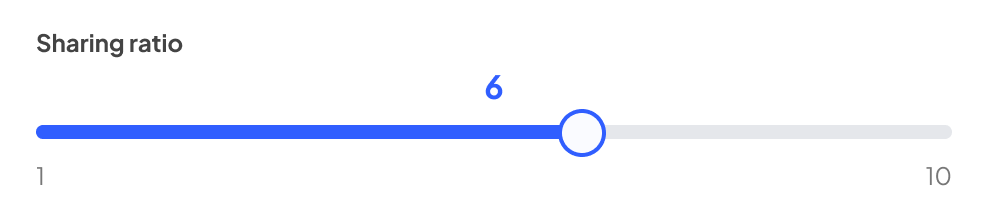
1. GPU pool sharing ratio
This is where you can choose how much overcommit/oversubscription you allow for the GPU pool. Another way of thinking about it, is how many virtual GPUs can be created from each physical card in the pool.
With a sharing ratio of one, it’s a one-to-one mapping: you can share the resources of the pool once – i.e. provision the resources of the pool one time, to one team. You can also set this from 2 to 10, allowing oversubscription of the GPUs in the pool between 2 and 10 times – so with 4 GPUs in a pool, and a sharing ratio of 4, you’re actually presenting 16 virtual GPUs to your users.
As with any infrastructure as a service scenario, oversubscription (overselling) makes use of idle capacity to serve additional customers. It’s the basis of efficient and profitable service delivery.
Why would you need a sharing ratio of one?
At first glance you might think this is a redundant option. However, it’s very different from just providing one card per user (the passthrough model) because you’re actually sharing the entire pool of GPUs with a team of users.
There is more flexibility, because the team can have varying levels of access to multi-GPU resources. There is more scalability, because the pool can be expanded by adding more GPUs; and there is more redundancy, because if a GPU fails, the rest of the pool is still available.
2. GPU pool optimization
This slider controls how the scheduler allocates the resources of the GPU pool to workloads, to prefer performance, security, or a blend of both.
Security: using temporal scheduling, hosted·ai swaps user tasks in and out of the GPU. It’s a little like time-slicing, except for a crucial difference: each task has full isolated access to the GPU during its allocated time. The scheduler context-switches tasks extremely rapidly; at no time do user tasks co-exist in the GPU.
Performance: using spatial scheduling, hosted·ai fits user tasks into the GPU resources available to maximize utilization. User tasks co-exist on the GPU. This is a little like MIG, but the resource allocation is dynamic and scales to the requirement of the workloads. Because there is no task-switching this improves performance, which can benefit latency-sensitive inference workloads.
Balanced: this uses temporal scheduling but relaxes the context-switching. It’s more secure than performance mode, and more performant than security mode.
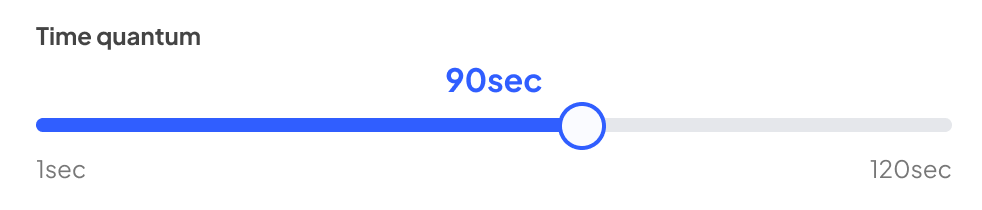
3. GPU pool time quantum
For performance and balanced pool settings (i.e. temporal scheduling) this setting controls the time a task has access to the full resources of a GPU.
The scheduler takes this into account for user workloads accessing the pool, and adjusts their access accordingly: lower settings equate to lower latency.
Future scheduler enhancements
As more enterprises adopt AI, especially inferencing, and as more Neoclouds, CSPs and Telcos build multi-tenant GPUaaS to serve this market, we’re adapting our scheduler to cater for this fast-evolving landscape.
Coming next is a new credit-based scheduling system that provides a kind of automatic balancing of mixed inference/training workloads, and we’ll be sharing more details soon.
Multi-tenant GPU FAQs
True multi-tenant GPU is a new approach and you’ll certainly have questions. If you’d like to know more about how this works, why not get in touch for a discussion and a demo?
In the meantime, here are some FAQs…
What happens when we run out of VRAM?
If you know how multi-tenant virtualization works, you’ll obviously be asking this question. RAM is always a limiting factor in the number of tenants possible on a given piece of hardware, and GPU VRAM is no different. There are two answers here.
First, the hosted·ai scheduler makes optimal use of the resources available – fitting workloads into available VRAM with spatial scheduling, to maximize utilization, or simply allowing multiple workloads to have full access to GPU VRAM, with temporal scheduling. That’s obviously more efficient than just assigning an entire card to a user regardless of how much of the VRAM they actually need or consume.
Secondly, we use system RAM for workloads if there is insufficient VRAM available. System RAM is not as fast as high-end VRAM but it provides a robust way to handle this scenario. It may increase the system RAM requirement for GPU nodes, resulting in a slight increase in server cost, but compared to the cost of a single GPU the system RAM cost is somewhat irrelevant.
What happens to context-switched tasks?
System RAM is also used when tasks are switched out of a GPU in pools configured for temporal scheduling (maximum security or balanced optimizations).
What about the performance overhead?
It’s virtualization, so of course there is a small hit to performance. If you want to provide customers with 100% “ownership” of a single GPU, you can do that with hosted·ai, but for the vast majority of use cases the huge increase in flexibility offered by software-defined GPU prefers the multi-tenant approach:
In performance mode, tasks are running in parallel – so for inferencing, with periodic queries, tasks won’t see any disruption to performance as long as they are consuming GPU within the bounds they are allocated.
In security mode, tasks are switched in and out of the GPU. Context-switching is opportunistic, and the hosted·ai scheduler uses an extremely fast detection algorithm to control that switching, with the time quantum setting providing additional control. There is a trade-off between security and performance, as always, but with modern server architectures it is not “slow”.
Balanced mode provides a mix of the two, of course, and is often the preferred scheduling method – but this is something for service providers to decide when testing the platform and working with their own customers. What we provide you in the hosted·ai platform is the choice and the ability to control it.
We’re excited to announce the availability of hosted·ai v2.0.1, with new features to make GPUaaS even easier to manage and sell. Let’s get into it!
#BuildingInPublic – the platform story so far
In August 2025 we released hosted·ai v2.0, which consolidated many stability and security improvements we brought to the platform throughout the year. We consider that to be our first stable release, and we generally have a monthly release cycle – so from now on, we’ll talk each month about new features in the platform, and what’s coming next.
hosted·ai handles GPU very differently to other GPUaaS platforms. Our GPU control plane enables 100% GPU utilization by combining individual GPUs into pools, and allowing the resources of the entire pool to be shared with multiple tenants at once.
The hosted·ai platform has an extremely efficient task scheduler that context-switches tasks in and out of physical GPUs in the pool – but, how is this scheduling controlled?
Introducing… the new GPU optimization slider.
When you create a GPU pool, you assign GPUs to the pool and choose the sharing ratio – i.e. how many tenants the resources of the pool can be allocated/sold to. For any setting above 1, the new optimization slider becomes available.
Behind this simple slider is a world of GPU cloud flexibility. The slider enables providers to configure each GPU pool to suit different customer use cases. Here’s a quick demo from Julian Chesterfield, CTO at hosted·ai:
GPUaaS optimized for security Temporal scheduling is used. The hosted·ai scheduler switches user tasks completely in and out of physical GPUs in the pool, zeroing the memory each time. At no point do any user tasks co-exist on the GPU. This is the most secure option, but comes with more performance overhead.
GPUaaS optimized for performance Spatial scheduling is used. The hosted·ai scheduler assigns user tasks simultaneously to make optimal use of the GPU resources available. There is no memory zeroing. This is the highest-performance option, but it doesn’t isolate user tasks – they are allocated to GPUs in parallel.
Balanced GPUaaS Temporal scheduling is used, but without fully enforced memory zeroing. This provides a blend of performance and security.
Why is this important?
Service providers need the flexibility to handle any mix of heterogeneous workloads. That’s just as true for GPUaaS as it is for traditional IaaS cloud and hosting.
Your GPUaaS needs to cater to a range of price/performance targets for different AI model training, tuning and inference use cases, as well as customers in simulation, gaming, research and so on.
The hosted·platform enables you to configure your infrastructure and services accordingly:
Creating pools of different GPU classes
Configuring the sharing, security and performance characteristics of each pool
Configuring pricing and other policies for each pool
Enabling customers to subscribe to any mix of pools for different workloads
2. Self-service GPU / end user enhancements
Also in this release, some handy improvements for end users running their applications in your hosted·ai environments:
GPU application service exposure
We’re made it easier to expose ports for end user applications and services through the hosted·ai admin panel (and coming soon, through the user panel).
Now your customers can choose how they present their application services to the outside world, through configurable ports
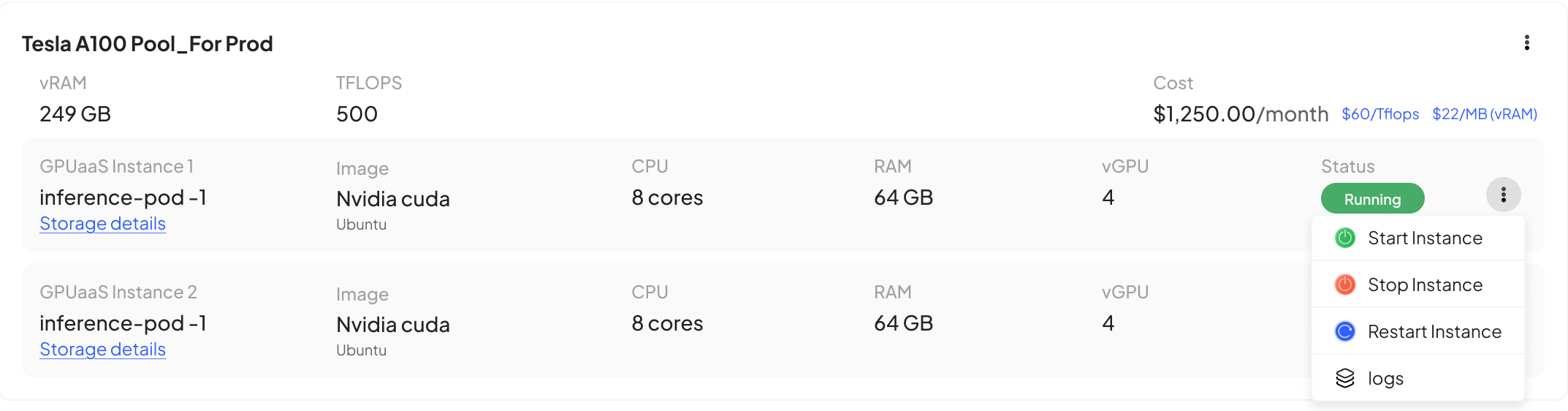
Self-service GPU pool management
We’ve added new management tools for your customers too. Each GPU resource pool they subscribe to can be managed through their user panel, with visibility of the status of each pod; the ability to start, stop and restart pods; and logs with information about the applications using GPU.
Why are these things important?
These enhancements are part of our mission to make GPUaaS as fast and frictionless as possible for your end users (e.g. nobody should be forced to use CLI and dive into K8s just to restart a service)
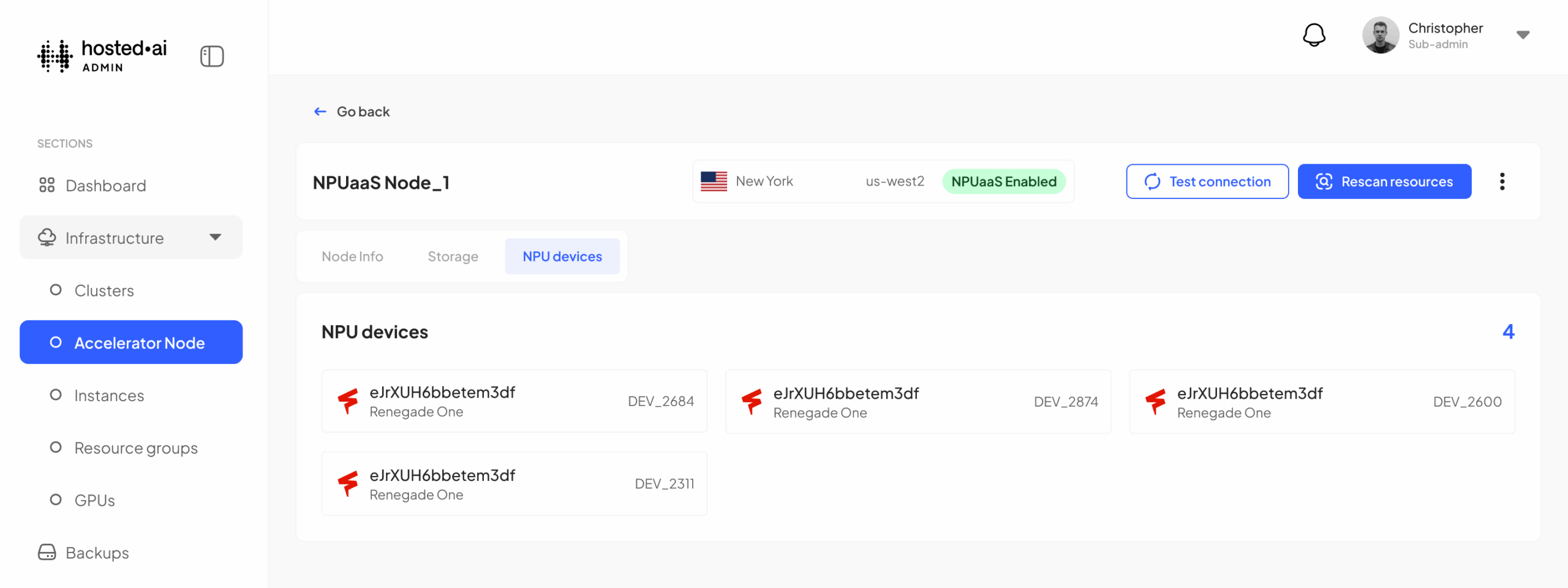
3. Furiosa device integration
In July 2025 we announced our partnership with Furiosa, a semiconductor company specializing in next-generation AI accelerator architectures and hardware. We’ve been working to bring Furiosa device support to hosted·ai and this is now available in v2.0.1.
Now service providers can create regions with clusters based on Furiosa, as well as NVIDIA. Once a region has been set up for Furiosa, it can be managed, priced and sold using the same tools hosted·ai makes available for NVIDIA – and in future, other accelerator devices.
Why is this important?
Furiosa’s Tensor Contraction Processor architecture is designed to maximize performance per dollar and per watt for generative AI workloads. The hosted·ai platform is designed to be accelerator-agnostic to give service providers flexibility in the AI infrastructure they build and sell. It’s all about flexibility to meet different use cases at different price/performance points.
More information:
New to hosted·ai? Get in touch for a chat and/or demo
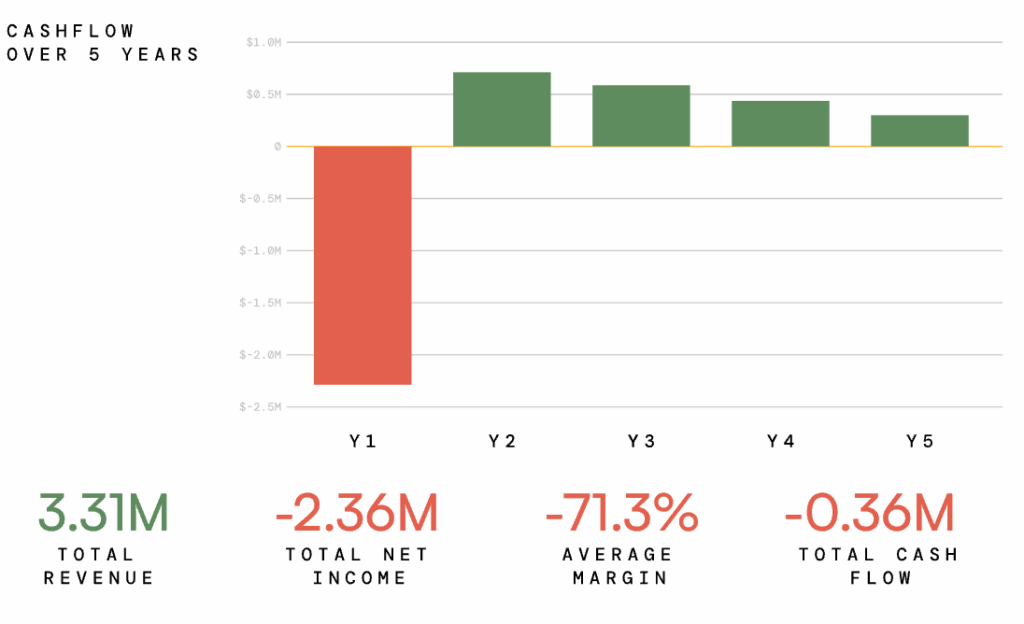
Most Neoclouds have a problem: it’s hard to see a future where the business is actually profitable.
Some companies in this space have already folded. Many more are struggling to make the numbers add up, because super-high GPU capex + low utilization + price erosion + commoditization = little or no ROI.
Let’s fix that.
Everyone agrees that AI is the future, but how do you build an infrastructure business for AI that will still be in business next year, let alone in five years’ time?
Get your copy of the Neocloud Survival Guide, and learn how to 5x your GPU revenue and margin.
We celebrated our first anniversary in August 2025. To mark the occasion, we hosted our four co-founders for a coffee and chat. We touched upon their journey so far, the service provider industry, and their aspirations with hosted·ai.
Santa Clara, CA – 30th September 2025 –hosted·ai has signed a strategic partnership with Maerifa Solutions, a leading digital infrastructure company focused on the provision of technology design, deployment and supply chain management services. The partnership aims to facilitate the rapid creation and scaling of Neoclouds – cloud services built around GPU infrastructure for AI – by providing a one-stop shop for infrastructure advice, hardware, procurement and finance, and efficient, profitable GPU orchestration using hosted·ai software.
Maerifa simplifies Neocloud creation through its relationships with AI cloud infrastructure OEMs such as NVIDIA, Supermicro and Lenovo, and supply chain and finance partners who can support hardware procurement and purchasing. With hosted·ai, Maerifa can now also provide turnkey software for Neocloud orchestration and monetization, with easy-to-use tools for GPU cloud service design, pricing, metering, billing and self-service.
“The demand for GPU infrastructure is growing by leaps and bounds, however, there remains little focus developing multi-faceted Neoclouds with the ability to deliver the full catalogue of this infrastructure to end customers in a way that is economically viable long-term. Together with hosted.ai we have a solution that enables rapid scalability and will provide these companies with a way of focusing on what they are best at, attracting customers and providing innovative software solutions. We are already working on a number of projects together and invite others looking to grow their platforms to see how we can help,” said Rahul Kumar, Senior Executive Officer, Maerifa Solutions.
“There is huge demand for AI training and inference infrastructure, but Neoclouds face quite a few challenges to deliver the scale that the market needs,” said Narendar Shankar, Chief Commercial Officer at hosted·ai. “Our partnership with Maerifa is exciting news for companies in this space, because they now have one expert partner for sourcing and delivering GPU infrastructure, and getting help with financing; and combined with hosted·ai, the software to manage, provision and bill for AI cloud services while making those services efficient and profitable.”
hosted.ai was founded to make GPU cloud efficient, easy and profitable for service providers, by creating a turnkey GPUaaS platform designed specifically for companies in this market. hosted.ai was launched in 2024 by a team with deep experience of owning, running, and building solutions for AI and for service providers, at businesses including VMware, Nvidia, Expedia, XenSource, OnApp, Sunlight and UK2.
Maerifa Solutions was conceived, incubated and launched by Aethlius Holdings to create an ecosystem of Tier-1 partners across Digital Infrastructure and related financing solutions delivered by its partners to address the funding gap of acquiring hard-to-access GPU server technology. Since its launch in Q3 2024 it has already partnered with leading players in the industry and is in discussions to deliver multi-million dollars’ worth of hardware and associated solutions to projects in Europe, Middle East, Africa and Southeast Asia.
About hosted·ai hosted·ai provides software to make AI infrastructure hosting simple and profitable for service providers. The hosted·ai platform is a turnkey AI cloud / GPUaaS stack that gives service providers the tools they need to create, manage and monetize GPU cloud infrastructure. hosted·ai was founded in 2024, launched publicly in 2025 and has teams across the US, EMEA and Asia-Pacific. For more information, visit https://hosted.ai.
About Maerifa Solutions Maerifa Solutions is an ADGM-registered digital infrastructure company, in collaboration with its extensive ecosystem, brings expertise in technology design and deployment, supply chain management, data centers, and power solutions. This, combined with Maerifa Solutions’ deep financial acumen, enables it to deliver creative investment solutions that help clients realise the full potential of AI infrastructure. By offering innovative funding mechanisms and access to hardware and hosting capacity, Maerifa Solutions ensures the long-term scalability and capital efficiency of AI projects.
Redefining price/performance/power for AI cloud deployments with next-generation inference hardware
Santa Clara, CA – 8th July 2025 – FuriosaAI, a pioneering leader in next-gen AI semiconductor, today announced a strategic partnership with hosted·ai to deliver ultra-efficient, high-performance AI infrastructure built on Furiosa’s Tensor Contraction Processor (TCP) architecture. The hosted·ai cloud platform will fully support Furiosa’s flagship RNGD (pronounced “Renegade”) processors, enabling service providers to leverage TCP-powered infrastructure for hosting AI workloads.
hosted·ai is a turnkey AI cloud platform for service providers. It delivers multi-tenant virtualization of infrastructure for AI inference and training, with full software-defined control and oversubscription of hardware accelerators such as RNGD and GPUs. This enables service providers to pool the resources of multiple accelerators, provision those resources on demand to multiple clients, and sell 4x-10x the physical capacity available. As a result they can price their offerings competitively and improve unit economics, achieving higher revenue with an increasing average margin.
The new partnership will add support for Furiosa’s flagship RNGD Processor for LLM and agentic AI inference to the hosted·ai platform. RNGD leverages Furiosa’s Tensor Contraction Processor (TCP) chip architecture, which solves the fundamental hardware challenge of running AI algorithms: providing not just raw compute power, but also using that compute effectively and efficiently to deliver excellent real-world performance.
“We’re excited by this partnership and its potential to transform the cost and impact of AI infrastructure,” said Furiosa’s SVP of Product and Business, Alex Liu. “Furiosa’s processors are purpose-built for AI and represent a huge leap forward in performance per watt compared to GPUs thanks to our Tensor Contraction Processor (TCP) architecture. hosted·ai has the same devotion to efficiency and performance in its AI cloud software stack, enabling service providers to properly virtualize the accelerator and maximize utilization. This unique combination delivers the best solution for sovereign service provider AI clouds.”
“This partnership is an important step in our mission to make AI infrastructure accessible and affordable for service providers and their customers,” said Ditlev Bredahl, CEO of hosted·ai. “Together we’ll bring new ways for service providers to accelerate AI workloads with reduced hardware CAPEX and OPEX, optimal utilization, sustainable profitability for their business, and the best price/performance for their customers.”
Availability of Furiosa RNGD support in the hosted·ai platform is expected by the end of 2025. Looking ahead, the two companies plan to develop an off-the-shelf appliance for service provider AI cloud, combining hosted·ai software, Furiosa accelerators, and rack server modules for easy turnkey adoption by service providers.
About hosted·ai hosted·ai provides software to make AI infrastructure and GPUaaS simple and profitable for service providers. The hosted·ai platform fully virtualizes AI datacenter infrastructure, including GPUs and other hardware accelerators. This makes it possible to share and utilize 100% of hardware resources with users in a secure multi-tenant environment, which reduces the overall hardware requirement, minimizes idle resources, and dramatically changes the cost/revenue/margin equation for AI cloud service providers. For more information, visit https://hosted.ai.
About furiosa.ai FuriosaAI is building a new class of AI processor for enterprise and data center workloads. Powered by the Tensor Contraction Processor (TCP) architecture, Furiosa delivers sustainable, high-efficiency AI compute designed from the ground up for modern inference applications. Its mission is to democratize powerful AI through AI-native designed ASICs and software stack, giving everyone on Earth access to powerful AI. For more information, please visit furiosa.ai.
Making GPUaaS work for service providers and the mainstream AI hosting market
You’re not virtualizing GPU the wrong way – you’re just not doing it the optimal way for maximum utilization, flexibility and ROI from your hardware investments.
This high-level whitepaper explains the difference between GPU virtualization and true GPU as a Service (GPUaaS).
It explores the benefits and drawbacks of GPU passthrough, instancing and slicing, and explains why service provider GPUaaS requires a different approach – especially for AI inference workloads. To get your free copy, just fill out the form.
GPU-as-a-Service is a huge opportunity for the cloud hosting industry – but what kind of GPUaaS should you launch to compete, grow and make serious money selling AI hosting? In this 30-minute session we explore three go-to-market playbooks for GPUaaS.
Speakers:
Ditlev Bredahl
CEO
hosted·ai
Narendar Shankar
CCO
hosted·ai
What will you learn?
We’ll give you a quick introduction to hosted·ai, and how it overcomes the drawbacks of the way that GPU cloud is built and sold today. Then, we’ll focus on the opportunities this creates for service providers to fill those gaps in the market, with three suggested GPUaaS playbooks:
Developer-Focused GPUaaS: why not build a DigitalOcean for GenAI? Here’s how we’d do it.
SLA-Focused GPUaaS: the Neoclouds might be super-rich, but their service levels don’t make sense. You can do better, of course.
By The Numbers: in today’s GPUaaS market there is a LOT of space to adjust price and margin in your favor, in your customers’ favor, or both.
We value your privacy
We use cookies to enhance your browsing experience, serve personalized ads or content, and analyze our traffic. By clicking Accept All you consent to our use of cookies.
Cookie Settings
We use cookies to improve your experience on our website. You can choose which categories of cookies to allow:
These cookies are essential for the website to function properly and cannot be disabled.
Help us understand how visitors interact with our website by collecting anonymous information.
Used to track visitors across websites for advertising and personalized content.
Remember your preferences and settings to provide a personalized experience.




"%3E%3Cpath d="M16 3C13.4288 3 10.9154 3.76244 8.77759 5.1909C6.63975 6.61935 4.97351 8.64968 3.98957 11.0251C3.00563 13.4006 2.74819 16.0144 3.2498 18.5362C3.75141 21.0579 4.98953 23.3743 6.80762 25.1924C8.6257 27.0105 10.9421 28.2486 13.4638 28.7502C15.9856 29.2518 18.5995 28.9944 20.9749 28.0104C23.3503 27.0265 25.3807 25.3603 26.8091 23.2224C28.2376 21.0846 29 18.5712 29 16C28.9964 12.5533 27.6256 9.24882 25.1884 6.81163C22.7512 4.37445 19.4467 3.00364 16 3ZM21.7075 13.7075L14.7075 20.7075C14.6146 20.8005 14.5043 20.8742 14.3829 20.9246C14.2615 20.9749 14.1314 21.0008 14 21.0008C13.8686 21.0008 13.7385 20.9749 13.6171 20.9246C13.4957 20.8742 13.3854 20.8005 13.2925 20.7075L10.2925 17.7075C10.1049 17.5199 9.99945 17.2654 9.99945 17C9.99945 16.7346 10.1049 16.4801 10.2925 16.2925C10.4801 16.1049 10.7346 15.9994 11 15.9994C11.2654 15.9994 11.5199 16.1049 11.7075 16.2925L14 18.5863L20.2925 12.2925C20.3854 12.1996 20.4957 12.1259 20.6171 12.0756C20.7385 12.0253 20.8686 11.9994 21 11.9994C21.1314 11.9994 21.2615 12.0253 21.3829 12.0756C21.5043 12.1259 21.6146 12.1996 21.7075 12.2925C21.8004 12.3854 21.8741 12.4957 21.9244 12.6171C21.9747 12.7385 22.0006 12.8686 22.0006 13C22.0006 13.1314 21.9747 13.2615 21.9244 13.3829C21.8741 13.5043 21.8004 13.6146 21.7075 13.7075Z" fill="%235F8C5E"/%3E%3C/g%3E%3Cdefs%3E%3CclipPath id="clip0_1444_18914"%3E%3Crect width="32" height="32" fill="white"/%3E%3C/clipPath%3E%3C/defs%3E%3C/svg%3E%0A)
"%3E%3Cpath d="M16 3C13.4288 3 10.9154 3.76244 8.77759 5.1909C6.63975 6.61935 4.97351 8.64968 3.98957 11.0251C3.00563 13.4006 2.74819 16.0144 3.2498 18.5362C3.75141 21.0579 4.98953 23.3743 6.80762 25.1924C8.6257 27.0105 10.9421 28.2486 13.4638 28.7502C15.9856 29.2518 18.5995 28.9944 20.9749 28.0104C23.3503 27.0265 25.3807 25.3603 26.8091 23.2224C28.2376 21.0846 29 18.5712 29 16C28.9964 12.5533 27.6256 9.24882 25.1884 6.81163C22.7512 4.37445 19.4467 3.00364 16 3ZM21.7075 13.7075L14.7075 20.7075C14.6146 20.8005 14.5043 20.8742 14.3829 20.9246C14.2615 20.9749 14.1314 21.0008 14 21.0008C13.8686 21.0008 13.7385 20.9749 13.6171 20.9246C13.4957 20.8742 13.3854 20.8005 13.2925 20.7075L10.2925 17.7075C10.1049 17.5199 9.99945 17.2654 9.99945 17C9.99945 16.7346 10.1049 16.4801 10.2925 16.2925C10.4801 16.1049 10.7346 15.9994 11 15.9994C11.2654 15.9994 11.5199 16.1049 11.7075 16.2925L14 18.5863L20.2925 12.2925C20.3854 12.1996 20.4957 12.1259 20.6171 12.0756C20.7385 12.0253 20.8686 11.9994 21 11.9994C21.1314 11.9994 21.2615 12.0253 21.3829 12.0756C21.5043 12.1259 21.6146 12.1996 21.7075 12.2925C21.8004 12.3854 21.8741 12.4957 21.9244 12.6171C21.9747 12.7385 22.0006 12.8686 22.0006 13C22.0006 13.1314 21.9747 13.2615 21.9244 13.3829C21.8741 13.5043 21.8004 13.6146 21.7075 13.7075Z" fill="%235F8C5E"/%3E%3C/g%3E%3Cdefs%3E%3CclipPath id="clip0_1444_18919"%3E%3Crect width="32" height="32" fill="white"/%3E%3C/clipPath%3E%3C/defs%3E%3C/svg%3E%0A)
"%3E%3Cpath d="M16 3C13.4288 3 10.9154 3.76244 8.77759 5.1909C6.63975 6.61935 4.97351 8.64968 3.98957 11.0251C3.00563 13.4006 2.74819 16.0144 3.2498 18.5362C3.75141 21.0579 4.98953 23.3743 6.80762 25.1924C8.6257 27.0105 10.9421 28.2486 13.4638 28.7502C15.9856 29.2518 18.5995 28.9944 20.9749 28.0104C23.3503 27.0265 25.3807 25.3603 26.8091 23.2224C28.2376 21.0846 29 18.5712 29 16C28.9964 12.5533 27.6256 9.24882 25.1884 6.81163C22.7512 4.37445 19.4467 3.00364 16 3ZM21.7075 13.7075L14.7075 20.7075C14.6146 20.8005 14.5043 20.8742 14.3829 20.9246C14.2615 20.9749 14.1314 21.0008 14 21.0008C13.8686 21.0008 13.7385 20.9749 13.6171 20.9246C13.4957 20.8742 13.3854 20.8005 13.2925 20.7075L10.2925 17.7075C10.1049 17.5199 9.99945 17.2654 9.99945 17C9.99945 16.7346 10.1049 16.4801 10.2925 16.2925C10.4801 16.1049 10.7346 15.9994 11 15.9994C11.2654 15.9994 11.5199 16.1049 11.7075 16.2925L14 18.5863L20.2925 12.2925C20.3854 12.1996 20.4957 12.1259 20.6171 12.0756C20.7385 12.0253 20.8686 11.9994 21 11.9994C21.1314 11.9994 21.2615 12.0253 21.3829 12.0756C21.5043 12.1259 21.6146 12.1996 21.7075 12.2925C21.8004 12.3854 21.8741 12.4957 21.9244 12.6171C21.9747 12.7385 22.0006 12.8686 22.0006 13C22.0006 13.1314 21.9747 13.2615 21.9244 13.3829C21.8741 13.5043 21.8004 13.6146 21.7075 13.7075Z" fill="%235F8C5E"/%3E%3C/g%3E%3Cdefs%3E%3CclipPath id="clip0_1444_18924"%3E%3Crect width="32" height="32" fill="white"/%3E%3C/clipPath%3E%3C/defs%3E%3C/svg%3E%0A)







"%3E%3Cpath d="M16 3C13.4288 3 10.9154 3.76244 8.77759 5.1909C6.63975 6.61935 4.97351 8.64968 3.98957 11.0251C3.00563 13.4006 2.74819 16.0144 3.2498 18.5362C3.75141 21.0579 4.98953 23.3743 6.80762 25.1924C8.6257 27.0105 10.9421 28.2486 13.4638 28.7502C15.9856 29.2518 18.5995 28.9944 20.9749 28.0104C23.3503 27.0265 25.3807 25.3603 26.8091 23.2224C28.2376 21.0846 29 18.5712 29 16C28.9964 12.5533 27.6256 9.24882 25.1884 6.81163C22.7512 4.37445 19.4467 3.00364 16 3ZM21.7075 13.7075L14.7075 20.7075C14.6146 20.8005 14.5043 20.8742 14.3829 20.9246C14.2615 20.9749 14.1314 21.0008 14 21.0008C13.8686 21.0008 13.7385 20.9749 13.6171 20.9246C13.4957 20.8742 13.3854 20.8005 13.2925 20.7075L10.2925 17.7075C10.1049 17.5199 9.99945 17.2654 9.99945 17C9.99945 16.7346 10.1049 16.4801 10.2925 16.2925C10.4801 16.1049 10.7346 15.9994 11 15.9994C11.2654 15.9994 11.5199 16.1049 11.7075 16.2925L14 18.5863L20.2925 12.2925C20.3854 12.1996 20.4957 12.1259 20.6171 12.0756C20.7385 12.0253 20.8686 11.9994 21 11.9994C21.1314 11.9994 21.2615 12.0253 21.3829 12.0756C21.5043 12.1259 21.6146 12.1996 21.7075 12.2925C21.8004 12.3854 21.8741 12.4957 21.9244 12.6171C21.9747 12.7385 22.0006 12.8686 22.0006 13C22.0006 13.1314 21.9747 13.2615 21.9244 13.3829C21.8741 13.5043 21.8004 13.6146 21.7075 13.7075Z" fill="%235F8C5E"/%3E%3C/g%3E%3Cdefs%3E%3CclipPath id="clip0_1444_18909"%3E%3Crect width="32" height="32" fill="white"/%3E%3C/clipPath%3E%3C/defs%3E%3C/svg%3E%0A)